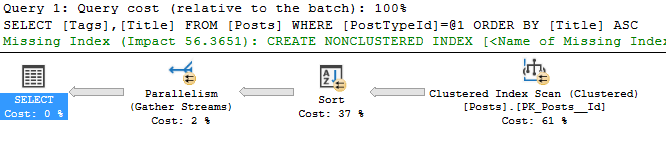
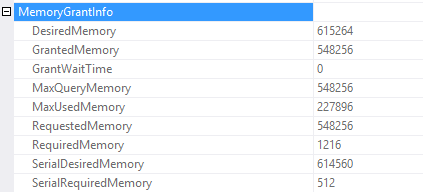
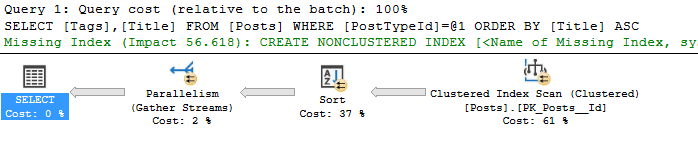
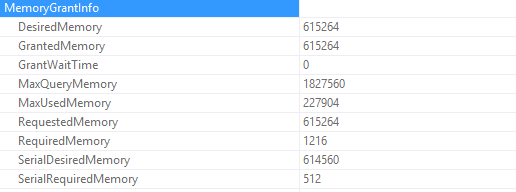
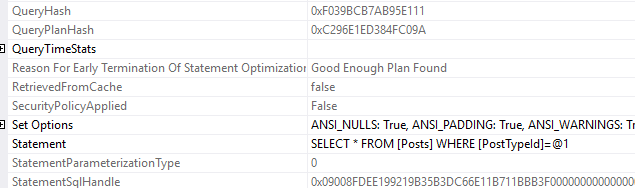
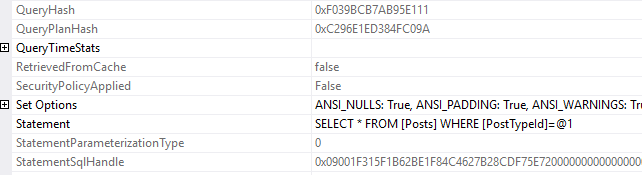
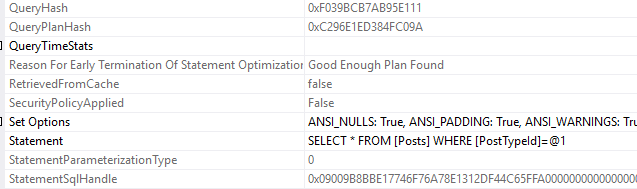
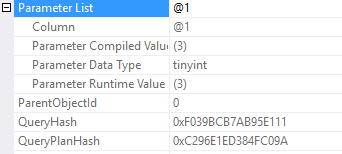
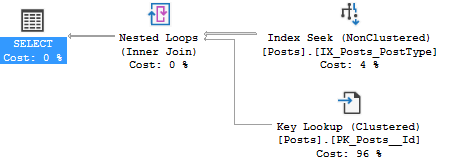
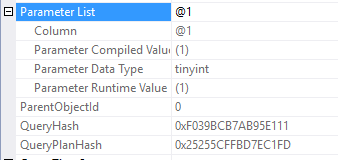
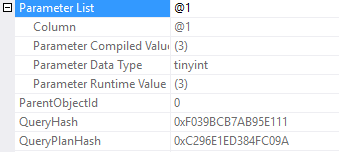
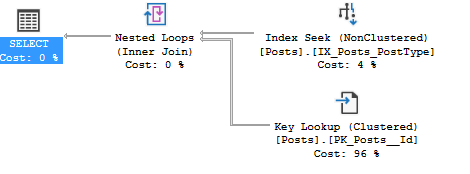
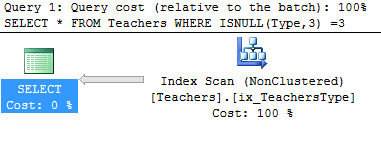
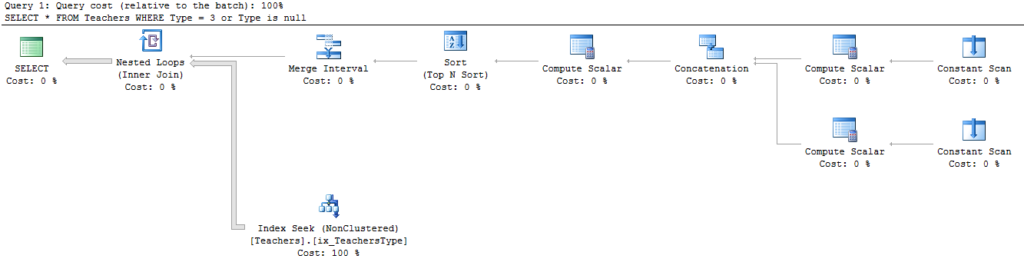
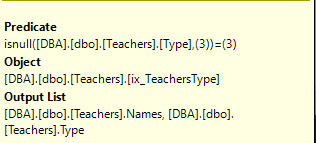
Wait statistics is the most important topic for analyzing database health. There’s three ways to do it.
sys.dm_os_wait_stats
This view is for system-wide analysis and the counters are cumulative since the last time your server was rebooted. Most scripts against this DMV will store the current values in a table, then wait for a specified amount of time before storing the new current values and comparing the difference.
That technique is great for analyzing overall system health because it gives you insights on every single wait statistic recorded during that time frame. However, I’ve found that this technique can be unreliable when my production systems are heavily pressured for CPU or memory.
sys.dm_os_waiting_tasks
As the name might imply, this view shows tasks that are currently waiting, along with their session_id, so you can use dm_exec_requests and dm_exec_sessions with this view to get detailed information on currently waiting sessions.
In my experience, this view is very reliable when there’s TempDB pressure on the system. It’s great, and I’m including my favorite script for this view below.
I don’t know who originally wrote this script, I found it in the “Diagnosing Latch Contention” whitepaper from the Microsoft Customer Advisory Team here.
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms descsys.dm_exec_session_wait_stats
New in SQL Server 2016, I haven’t used this DMV for wait statistics troubleshooting. If I can find a way this is useful, I’ll write a post!
Thanks for reading, stay tuned.