Update 2019-03-25:
I recently learned that my testing in this post may have been incorrect. The formula is supposed to still be applied at 25%. I’ll be working on this page over the next few days to get more accurate testing.
When you build a brand new shiny SQL Server, you want to get a lot of memory so your queries run faster, right? More memory for your data pages in the buffer pool and more memory for all the queries that keep sorting data in the database instead of the application.
However, I was just talking with a consultant friend, and she says that some servers are still running on 16 GB of memory out in Prod! At least that means this demo will be relevant, since that’s how much my demo laptop has.
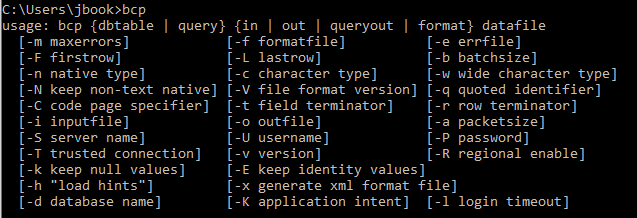
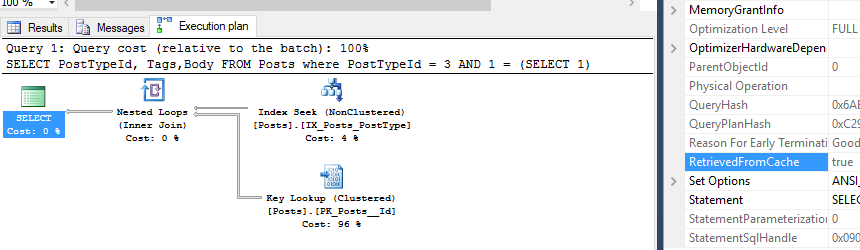
There’s a supposed to be a formula for max memory per query
Of course there’s a formula for it! I pulled the formula from the link, but when I started testing I saw different behavior on SQL Server 2016+. Let’s check the resource governor settings:
select * from sys.resource_governor_external_resource_pools
The formula in the link references 25%, but that was in an older version of SQL. I believe the formula on my SQL Server is
(Maximum SQL Server memory * 90%) * 20%
What fun would it be without a demo or two? Let’s dive right in. Here’s my current SQL Server settings.
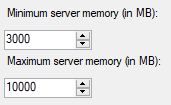
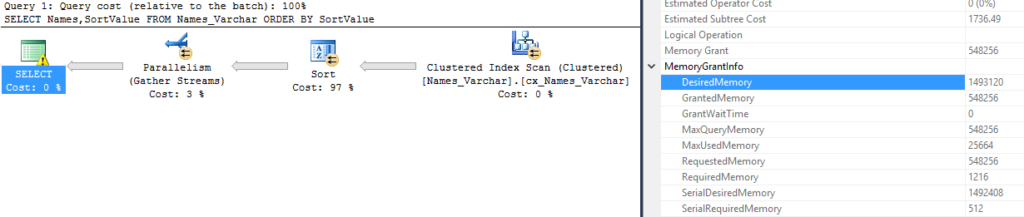
So, on my machine, we’ll expect to get a max grant of (10 GB * .90) *.20 = 1.8 GB. Here’s my table for a big memory grant.
CREATE TABLE BigMemoryGrant (Id INT IDENTITY(1,1), column1 NVARCHAR(max));
GO
CREATE CLUSTERED INDEX cx_BigMemoryGrant on BigMemoryGrant(Id);
GO
INSERT INTO BigMemoryGrant
SELECT 'A'
FROM sys.messages
INSERT INTO BigMemoryGrant
SELECT 'B'
FROM sys.messages
INSERT INTO BigMemoryGrant
SELECT 'C'
FROM sys.messages
If you’re wondering why I picked nvarchar(max), check out the other posts in this series! Anyway, here’s our query to request a lot of memory.
SELECT * FROM BigMemoryGrant
ORDER BY column1
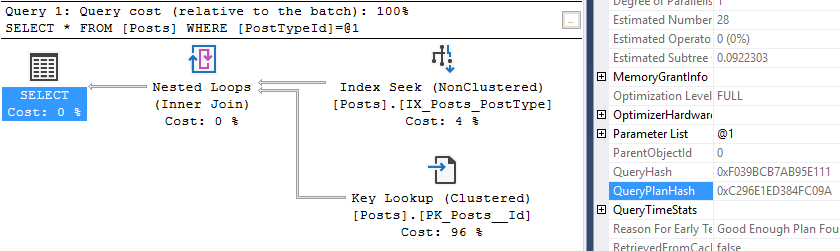
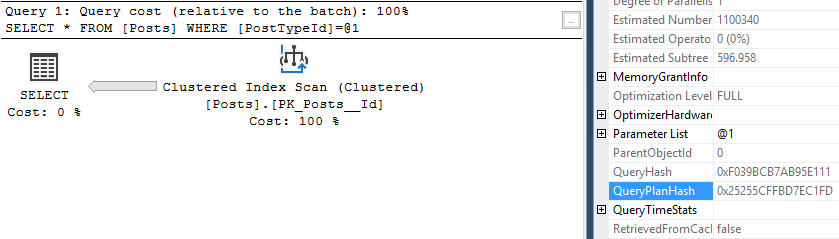
So we predicted 1.8 GB based on our formula, and we got a max grant just over 1.8 GB, that’s close enough for me!
I hope this was useful. If you add memory to your SQL Server, expect to see higher memory grants. Stay tuned!