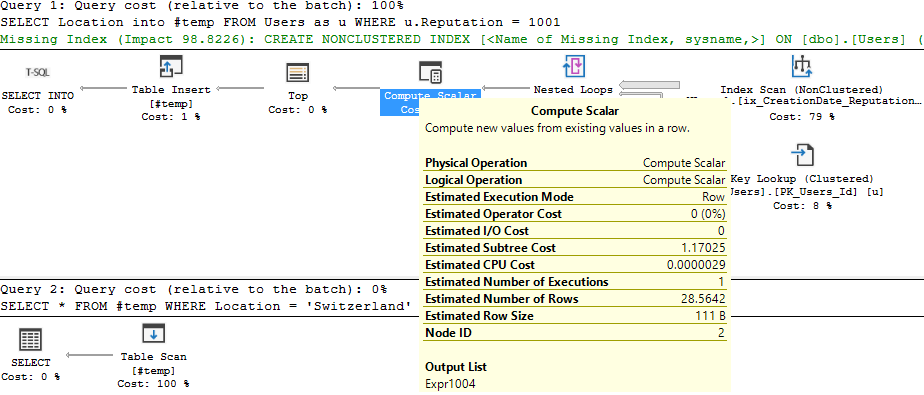
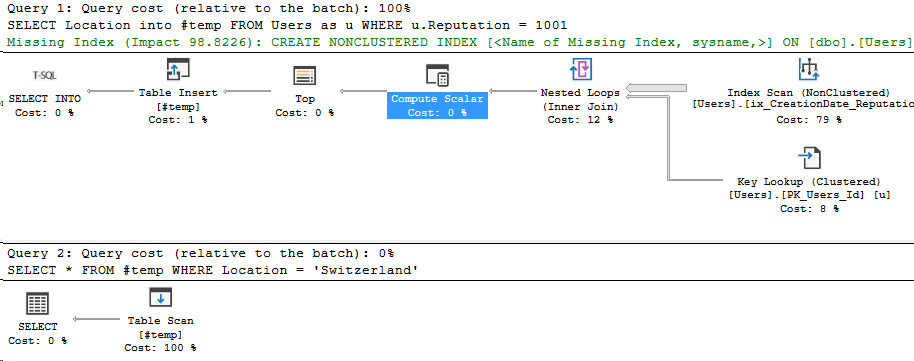
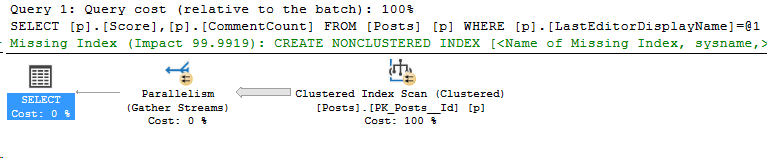
In Partitioning 2, I showed how to analyze which partitions were accessed by our Index Seek. However, we were searching the entire year’s partition for data. What if we filtered more specifically on the partitioning key?
Yesterday’s query: redux
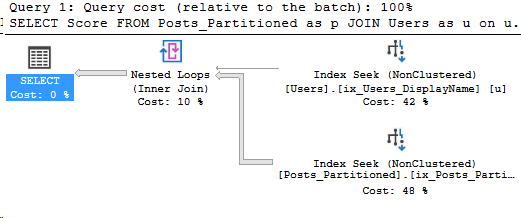
Taking the same query, but this time let’s just search for a single month of CreationDates. In part 2, the query for the entire year read 130 pages of the Posts table, and now we just want September:
SET STATISTICS IO ON;
SELECT Score FROM Posts_Partitioned as p
JOIN Users as u on u.Id = p.LastEditorUserId
WHERE u.DisplayName = 'Community'
AND p.CreationDate >= '2009-09-01' and p.CreationDate < '2009-10-01'
/*
(3590 rows affected)
Table 'Posts_Partitioned'. Scan count 1, logical reads 130,
physical reads 0, read-ahead reads 0, lob logical reads 0,
lob physical reads 0, lob read-ahead reads 0.
Table 'Users'. Scan count 1, logical reads 3, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
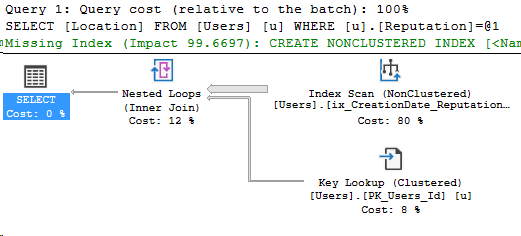
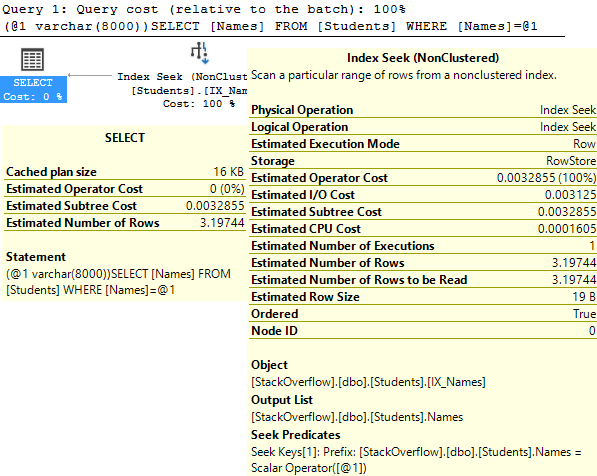
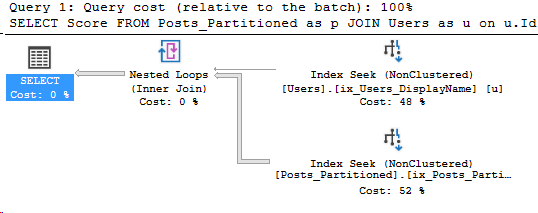
*/Here’s the execution plan for the new query as well:

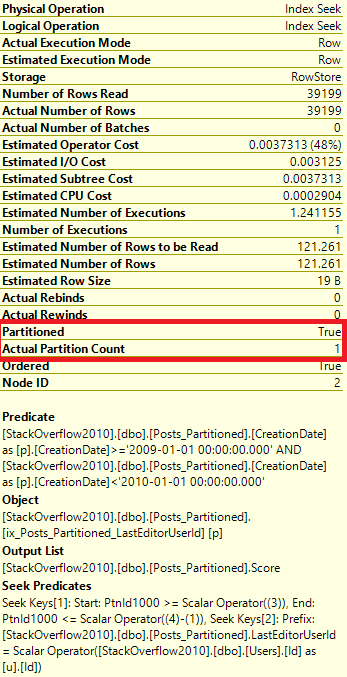
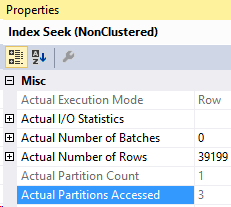
Details on the Posts_Partitioned Index Seek:
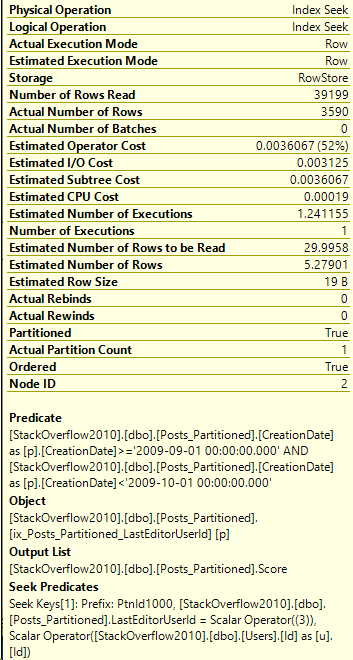
It’s a very similar execution plan, and the query looks fast. However, even though it returned less rows than the query in Partitioning 2, it still read the same amount of pages, 130.
Index design
At this point, we need to look at the index design. The index being used is defined as:
CREATE NONCLUSTERED INDEX ix_Posts_Partitioned_LastEditorUserId
ON Posts_Partitioned(LastEditorUserId)
INCLUDE (Score)
ON Posts_Partition_Scheme(CreationDate)
GOSo, let’s try changing the keys to see if we can get a better execution plan. First, let’s add CreationDate to the keys.
CREATE NONCLUSTERED INDEX ix_Posts_Partitioned_LastEditorUserId_CreationDate
ON Posts_Partitioned(LastEditorUserId,CreationDate)
INCLUDE (Score)
ON Posts_Partition_Scheme(CreationDate)
GOAnd re-running our query:
SET STATISTICS IO ON;
SELECT Score FROM Posts_Partitioned as p
JOIN Users as u on u.Id = p.LastEditorUserId
WHERE u.DisplayName = 'Community'
AND p.CreationDate >= '2009-09-01' and p.CreationDate < '2009-10-01'
/*
(3590 rows affected)
Table 'Posts_Partitioned'. Scan count 1, logical reads 16,
physical reads 0, read-ahead reads 0, lob logical reads 0,
lob physical reads 0, lob read-ahead reads 0.
Table 'Users'. Scan count 1, logical reads 3, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
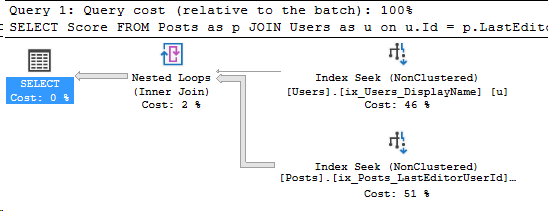
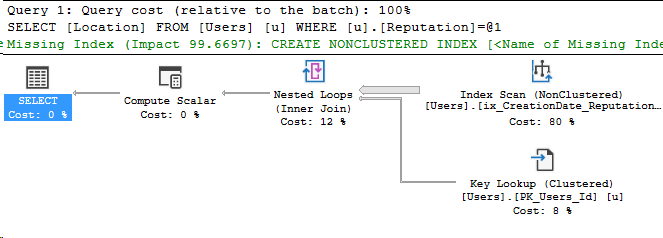
*/That’s a lot better! And here’s the index seek’s information:
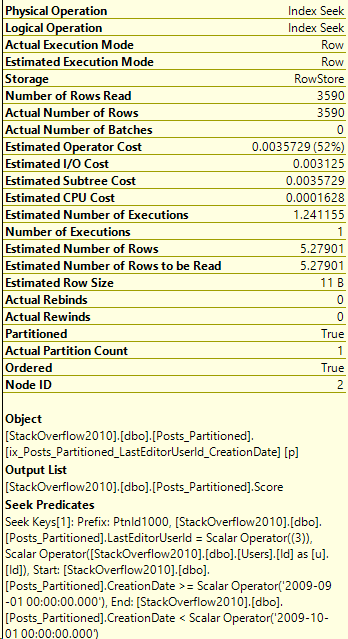
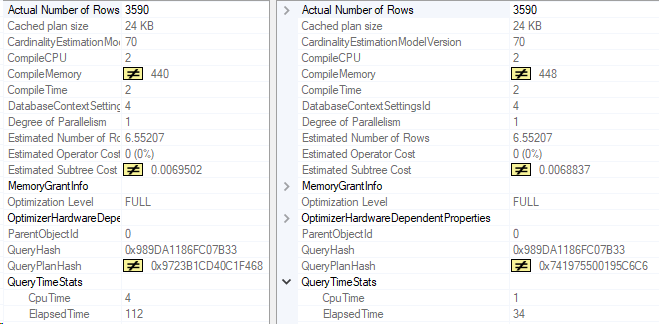
Even better. Let’s compare these two execution plans. The left side is with the original index, the right side is after, with the CreationDate key added.
What’s the moral of this post?
The point I want to make is that post-partitioning, you may have to re-think some of your existing indexes. Even if you add the partitioning key to all your queries, that can change your workload enough that you’ll want to examine your indexes.
Stay tuned!
P.S. What if we put CreationDate as the first key in the index?
I’ll drop the index used in this example, and create an index with CreationDate as the first key column.
DROP INDEX ix_Posts_Partitioned_LastEditorUserId_CreationDate
ON Posts_Partitioned
GO
DROP INDEX ix_Posts_Partitioned_LastEditorUserId
ON Posts_Partitioned
GO
CREATE NONCLUSTERED INDEX ix_Posts_Partitioned_CreationDate_LastEditorUser
ON Posts_Partitioned(CreationDate,LastEditorUserId)
INCLUDE (Score)
ON Posts_Partition_Scheme(CreationDate)
GOAnd now we re-run the query from above. Let’s take a look at the stats and the execution plan:
SET STATISTICS IO ON;
SELECT Score FROM Posts_Partitioned as p
JOIN Users as u on u.Id = p.LastEditorUserId
WHERE u.DisplayName = 'Community'
AND p.CreationDate >= '2009-09-01' and p.CreationDate < '2009-10-01'
/*
(3590 rows affected)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
Table 'Posts_Partitioned'. Scan count 1, logical reads 383,
physical reads 0, read-ahead reads 1, lob logical reads 0,
lob physical reads 0, lob read-ahead reads 0.
Table 'Users'. Scan count 1, logical reads 3, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
*/Ouch, that’s a lot more reads!
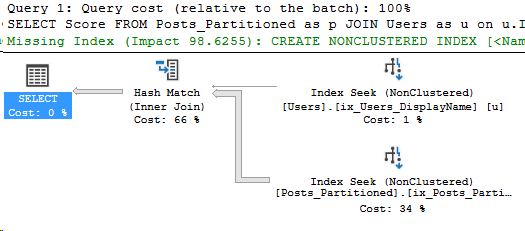
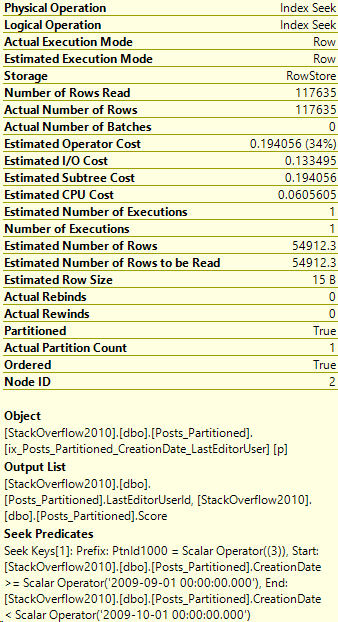
So with the key order of CreationDate first, our query got even worse than before! I hope this was an interesting side note.
Stay tuned!