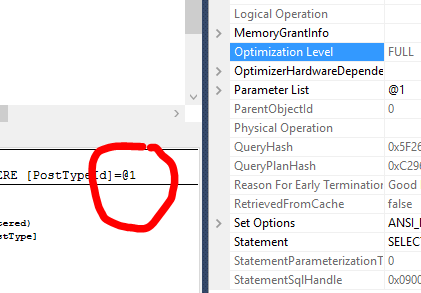
Part of query memory grants, part 4! This post will cover the wait type RESOURCE_SEMAPHORE briefly, but the focus is on what a semaphore is.
What the wait? Why does my system have RESOURCE_SEMAPHORE waits?
SQL Server only has so much memory to distribute to its queries. To decide who gets that memory, by default there’s two things called semaphores in SQL Server. Let’s take a look at the semaphores before we go any deeper.
SELECT
resource_semaphore_id,
total_memory_kb,
available_memory_kb,
grantee_count,
waiter_count,
pool_id
FROM sys.dm_exec_query_resource_semaphoresIf you want to see the documentation, click away.

So I said there’s two, but the DMV shows four. Why is that? Well, the answer is in the last column. There’s a pool_id. The pool_id comes from Resource Governor pools!
SELECT
pool_id,
name
FROM sys.dm_resource_governor_resource_pools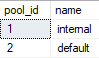
Okay, so we’ve established that there’s two semaphores for the default Resource Governor pool, which is where queries normally run. Don’t worry about the internal resource pool at this time.
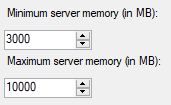
Some quick math on the available memory. My SQL Server has current max memory set to 10 GB. It looks like semaphore 0 has 7.3 GB available, and semaphore 1 has 300 MB allocated.
So how do the semaphores work? Why do they exist?
I think the best way to describe the semaphores would be to show them in a demo. Let’s do that.
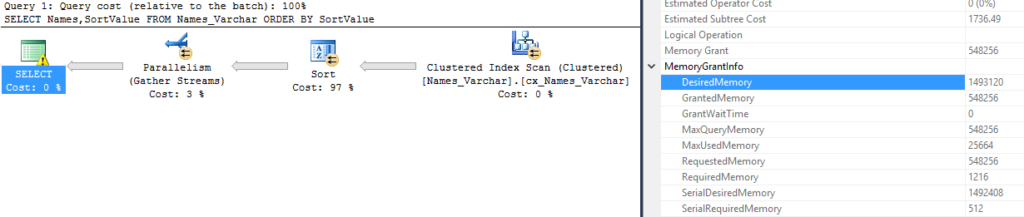
I’m going to take the query from Memory Grants part 3 because it uses a lot of memory.
SELECT * FROM BigMemoryGrant
ORDER BY column1Here’s the memory grant from that query:

Okay, we’re ready. Using SQLQueryStress , I’ll run the query eight times. Since our query’s memory grant is 1.8 GB and semaphore 1 is 300 MB, we’ll ignore this smaller semaphore. The big semaphore has 7.3 GB available, and we’re running eight queries so there won’t be enough room for all the queries.
SELECT
resource_semaphore_id,
total_memory_kb,
available_memory_kb,
grantee_count,
waiter_count,
pool_id
FROM sys.dm_exec_query_resource_semaphores
WHERE pool_id = 2
AND resource_semaphore_id = 0
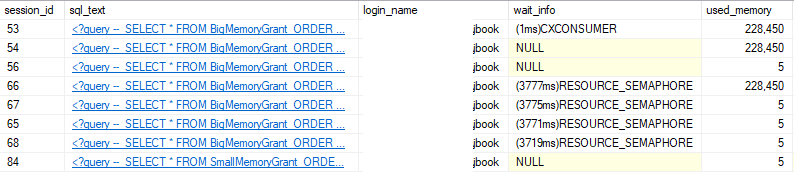
So according to this DMV, there’s only 3 queries with memory grants, while the remaining 5 queries have to wait for space in this semaphore. This is where the wait type comes in. When a query is sitting as a waiter, it will display the wait type RESOURCE_SEMAPHORE.
I don’t know why there’s extra available memory in this semaphore! It looks like there’s about 1,827,576 KB available and the query will request 1,827,560 so I’d think that one more query could get a memory grant. I’d be happy to know why though, if you know please leave a comment.
Here’s a quick look at what this same issue will look like in sp_WhoIsActive:

So what are these semaphores?
Think of them as a throttling mechanism for memory, to prevent all the server’s memory from being consumed. This way, there’s a system controlling access to the large semaphore, in this case semaphore 0.
The two systems are separate, so there’s still 300 MB available for queries that don’t need a lot of memory. Let’s take a look at a demo.
First, we need a table for a small memory grant. I’ll copy the script from part 3, but reduce the data size by a lot.
CREATE TABLE SmallMemoryGrant (Id INT IDENTITY(1,1), column1 NVARCHAR(max));
GO
CREATE CLUSTERED INDEX cx_SmallMemoryGrant on SmallMemoryGrant(Id);
GO
INSERT INTO SmallMemoryGrant
SELECT top 10 'A'
FROM sys.messages
INSERT INTO SmallMemoryGrant
SELECT top 10 'B'
FROM sys.messages
INSERT INTO SmallMemoryGrant
SELECT top 10 'C'
FROM sys.messages
--Run query once to see the memory grant size, get actual execution plan
SELECT * FROM SmallMemoryGrant
ORDER BY column1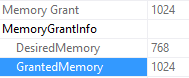
Great! Now, running our first workload of BigMemoryGrant eight times, and one execution of the SmallMemoryGrant.
Moral of the post: Query memory and how it fits into semaphores
So, while all the big memory grant queries are waiting for space in the big memory semaphore, the small memory grant query can run since there’s a separate semaphore for it.
I hope this was useful! Stay tuned for more in this memory grant series.