Disclaimer: I’m still learning PowerShell. I’ve been using it more lately and I want to talk about it more. I’ll blog about the commands that I find useful.
Get-Member
Think of this command as the help button.
This is my current favorite command for troubleshooting an existing script. In PowerShell, you can “pipe” any object to this command and it will describe the properties and methods of that object.
Knowing the properties, you can then use Get-Member again to get the properties of those properties. That’s not confusing, right? Uhh, maybe a little. Let’s look at some examples.
I’m going to use the PowerShell ISE for this example. When you start PowerShell, it begins in the User directory.
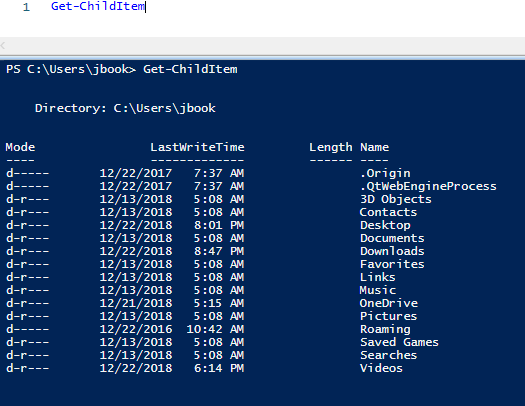
Then I’ll run Get-ChildItem, which will get all the objects inside the current directory.
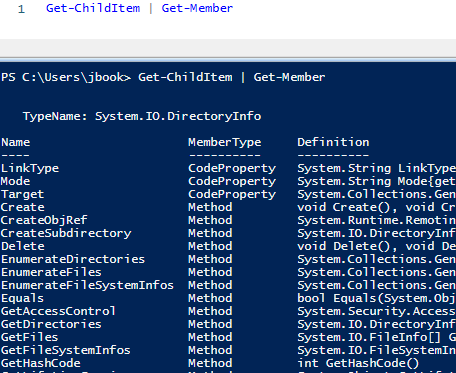
But what if I want to interact with those objects? I’ll need to know what their properties and methods are. That’s where Get-Member comes in!
Using the pipe to send the output to Get-Member
Simply send the output of any command to Get-Member.
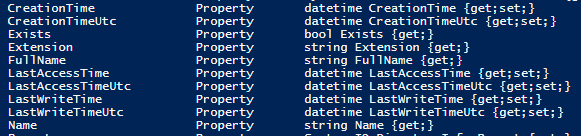
Now we know all the details about that directory. Here’s the properties from further down the list, which shows some of the columns that were displayed when we ran Get-ChildItem.
A query plan hash is a hash made from the operations in a specific execution plan. I’d like to say that every single execution plan has a different hash, but there might be one or two hash collisions out there.
Inside the execution plan, the specific costs per operator, amount of memory, and other resources values can change without changing the query plan hash. I’ll demo that later in this post.
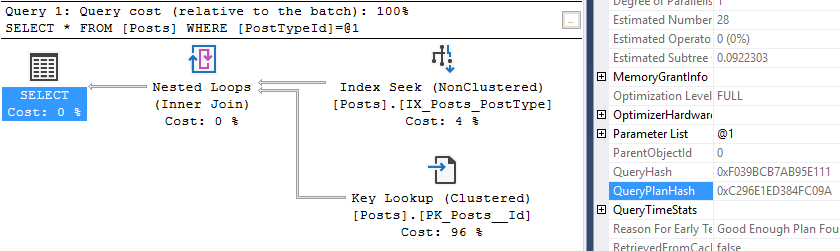
Let’s get right into the examples. First, the same query but different query plan hashes
Using the StackOverflow 2010 database, this is the same query from the query hash post, but I’m going to mix it up a little bit.
This query is a good example because the parameter of 3 will use a nonclustered index I created on PostTypeId. When I change the parameter to 1, the query will scan the Posts clustered index because there’s much more data for this parameter.
--PostTypeId 3 (Wiki posts in StackOverflow)
SELECT *
FROM Posts
WHERE PostTypeId = 3
Okay, our first query plan hash is 0xC296E1ED384FC09A, and the query hash is 0xF039BCB7AB95E111.
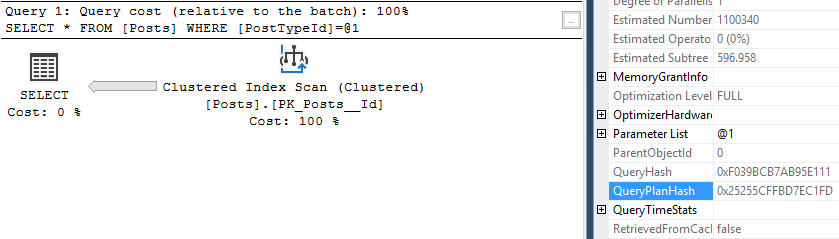
Now, I need a different execution plan, so I’ll change the value 3 to 1.
--PostTypeId 1 (Questions in StackOverflow)
SELECT *
FROM Posts
WHERE PostTypeId = 1
The query hash is the same, 0xF039BCB7AB95E111, but the execution plan is different. Now the query is just scanning the clustered index and the new query plan hash is 0x25255CFFBD7EC1FD.
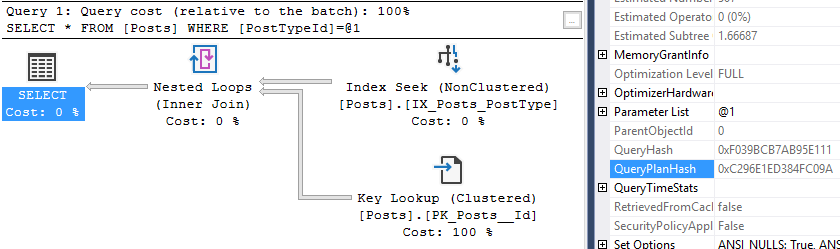
What if we change the parameter but the execution plan is the same? Will the query plan hash change?
Here’s another parameter that will generate the same execution plan shape as the first query, but with different costs and values.
--PostTypeId 4 (TagWikiExerpt)
SELECT *
FROM Posts
WHERE PostTypeId = 4
So we have the same query hash as the other two examples, and the same query plan hash as the first example. This time, with a slightly higher costs on the key lookup.
The morale of using the query plan hash
Often, people will talk about finding a “bad plan” in cache when they’re looking at poor performance and suspect that it’s due to parameter sniffing.
Here’s my take: Since one query can have more than one query plan, there could be many plan hashes. Any type of index change can also influence what plan is chosen, and change the query plan hash.
My recommendations
I recommend tracking and collecting the most expensive queries in your plan cache over time, and as part of that strategy, monitor for new query plan hashes on existing queries.
Thanks for reading! Stay tuned for the last part in this series, plan handle.
I like public speaking, but I haven’t always liked it. It started when I read Dale Carnegie’s book on public speaking, “The Art of Public Speaking,” while in college. If you’re interested, google search for a pdf on it, I believe at this point it’s available for free.
What I want to emphasis from this book
The whole book is 285 pages. That’s a lot of information, so I’ll summarize what I found to be the most useful.
Treat public speaking like a conversation with one person
I don’t recommend having a specific script with words that have to be said on each slide. I also don’t memorize the slides. If you’re reciting a script word-for-word, your presentation might come off as a textbook.
If you approach public speaking like a conversation between you and the entire audience (representing one singular entity), you can talk to them just like you talk to people every day.
If you mispoke in a 1-1 conversation, would it bother you?
I guess it depends on what you said, but I don’t think it would be a big deal. React the same way in your presentation. Mistakes happen, and the audience will understand if you correct yourself.
If you enjoyed this post or found it useful, please read some of the book. It seriously changed how I felt about public speaking.
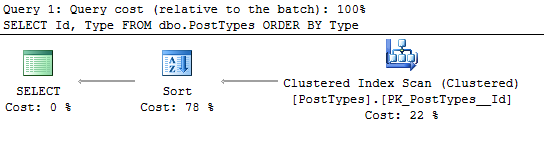
Let’s talk about how queries use memory, specifically in the execution plan. One of the query operators that use memory is sorting. To emphasize this, I’ll write a query with an order by clause, and look at the execution plan.
Query that will request a memory grant
Using StackOverflow2010 (Thanks to Brent Ozar and the Stack Overflow team for their data dump):
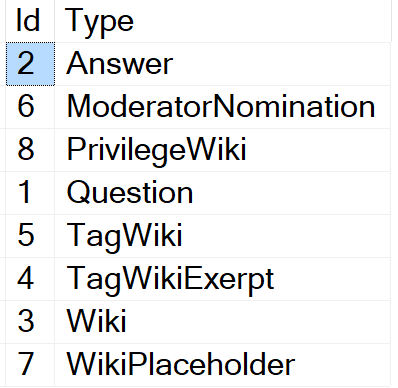
SELECT Id, Type
FROM dbo.PostTypes
ORDER BY Type
Here’s the results if you’re curious.
We want to look at the execution plan.
First, let’s look at the properties of the SELECT operator.
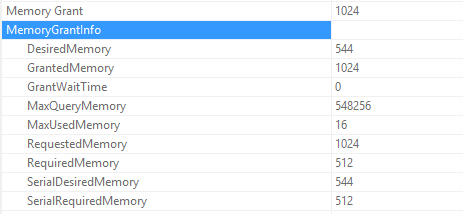
This is the memory grant for the entire query. Since we know that the Sort operator uses memory, let’s take a look at that operator and confirm that it used memory.
Where does the memory grant go?
We can confirm that the sort operator was requesting memory by looking at the operator’s memory fractions.
It gets harder from here. The execution plan is very useful for determining where the memory grants are coming, but once there’s multiple operators requesting memory grants, it gets much more complex.
For example, memory grants can be reused between operators in execution plans (source).
I want to continue this series and talk more about query memory usage. For those posts, please stay tuned!
If you’re on SQL Server 2016 or above, maybe you’re thinking about using the Query Store. That’s good! It’s an incredibly useful tool for performance tuning, and it can help you scale to handle performance on many servers.
There’s one thing I think you should know. The max size limit for the Query Store is not a hard limit.
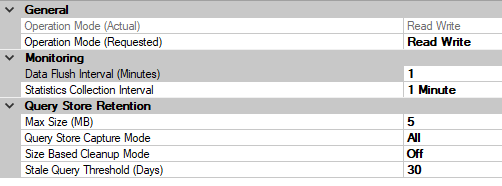
Controlling Query Store size
There’s a couple settings you can change to control the Query Store size. First, you want to set the Query Capture Mode to Auto, especially if you have an ad-hoc workload. There’s a great post by Erik Darling on BrentOzar.com about this setting. In summary, I recommend Auto to control the speed at which the Query Store grows.
Second, you can set the max size. You can do this in the database properties or with T-SQL, like so:
ALTER DATABASE [DBA]
SET QUERY_STORE (MAX_STORAGE_SIZE_MB = 100);
But the MAX_STORAGE_SIZE_MB is not a hard limit
I’ve seen this occur in production systems with heavy ad-hoc workloads. As the Query Store gathers data, there seems to be a point where the writes are queued up. When they are written to disk, the max size can be exceeded.
Anecdotally, I’ve seen a production systems where the max size has been vastly exceeded. But let me show you an example on a small scale on my demo machine.
Bad Query Store settings to reproduce this issue
To make this demo easy on my machine, I’m going to set the settings to the opposite of what I just recommended. Don’t use the settings below, this is just for the test.
Bad settings!
And now I need some ad-hoc bad queries to write to the Query Store. Here’s what I came up with. I ran the output of this query, and pretty much instantly over-filled the Query Store.
SELECT top 10000
N'SELECT N''' + REPLACE(text,N'''',N'')
+ N''' FROM sys.messages WHERE severity > 1 and text = '''
+ REPLACE(text,N'''',N'') + N''''
FROM sys.messages
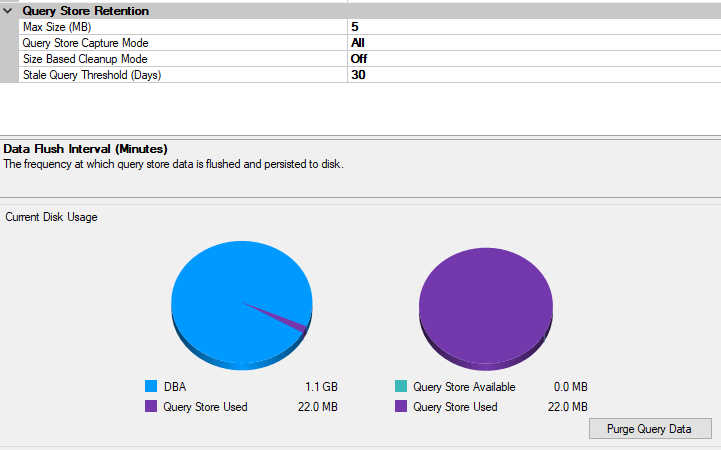
Now let’s look at the Query Store properties.
22 MB used of 5 MB max size.
Will this happen to my production system?
If you’re asking yourself if this will happen to you, I can’t answer that. First, make sure you have the right settings. Erin Stellato at SQL Skills has great advice on how to setup the Query Store.
I think this scenario is very unlikely in your system, unless you have very massive queries ad-hoc queries, and the Query Store setup incorrectly.
I know this post might sound obvious. This is a very rare problem. But this actually happened to me, and it might happen to you!
Suddenly, all queries on a test system were running slowly
One morning, I was called into a system where every single query was running slowly. System resources like CPU and memory were over-utilized, and it looked like the entire system was struggling to keep up.
I checked wait statistics, PerfMon, and sp_WhoIsActive. These just further reinforced the idea that the system was experiencing a heavier workload than normal.
How it was discovered
There’s actually a really simple query to find out if your indexes are disabled.
USE [Your-database-here]
GO
SELECT name from sys.indexes WHERE is_disabled = 1
Unfortunately, enabling indexes isn’t as easy
Here’s the snippet from SQL Server Management Studio on disabling/enabling indexes:
That’s right, in order to re-enable an index, you have to rebuild it. Ouch.
How did the indexes become disabled?
Well, to disable an index, you have to run an alter index script on each index. In my situation, a script that disabled indexes ran on the wrong environment.
Thanks for reading! Hopefully this rare issue doesn’t occur to you. Stay tuned!
This is one dangerous query hint. I wish I knew that when I started query tuning. I’ve used it before without fully understanding the impact.
What happens when a statement has OPTION(RECOMPILE)
SQL Server will compile an execution plan specifically for the statement that the query hint is on. There’s some benefits, like something called “constant folding.” To us, that just means that the execution plan might be better than a normal execution plan compiled for the current statement.
It also means that the statement itself won’t be vulnerable to parameter sniffing from other queries in cache. In fact, the statement with option recompile won’t be stored in cache.
The downsides
I have a few reasons why this hint is dangerous. First, compiling queries isn’t free. Using option recompile will use extra cpu and memory every time the statement compiles.
There’s also the fact that the hint applies strictly to the statement level, not the entire query. Let’s take a look at an example.
Reduce, reuse, recycle
I’m going to re-use the stored procedure from this post on parameter sniffing and using the estimated execution plan. Except for this example, I can’t use the estimated execution plan because there’s a temp table.
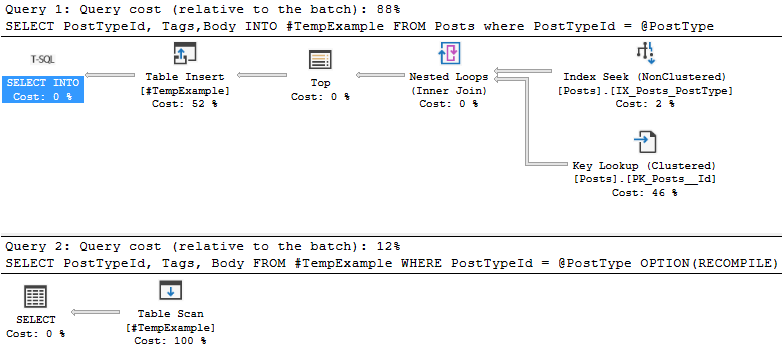
CREATE OR ALTER PROCEDURE [dbo].[QueryPostType_TempTable] (@PostType INT) as
BEGIN
SELECT PostTypeId, Tags,Body
INTO #TempExample
FROM Posts where PostTypeId = @PostType
SELECT PostTypeId, Tags, Body
FROM #TempExample
WHERE PostTypeId = @PostType
OPTION(RECOMPILE)
DROP TABLE #TempExample
END
GO
This stored procedure has OPTION(RECOMPILE) on only one statement
I’ll run the stored procedure with the value of 3, first.
exec [QueryPostType_TempTable] 3
Then, I’ll get the actual execution plan for post type 4.
exec [QueryPostType_TempTable] 4
Each “query” in this example is a separate statement. To prove that, I’ll right-click on the top SELECT INTO and view the properties.
Okay, but what about the cost of compilation?
To see the cost of compilation, just use statistics time. First, let’s create a simpler procedure.
CREATE OR ALTER PROCEDURE [dbo].[QueryPostType_OptionRecompile] (@PostType INT) as
BEGIN
SELECT PostTypeId, Tags,Body FROM Posts
JOIN Users as U on Posts.OwnerUserId = U.Id
JOIN Users as U2 on Posts.LastEditorUserId = U2.Id
WHERE PostTypeId = @PostType
OPTION(RECOMPILE)
END
GO
And then execute.
SET STATISTICS TIME ON;
EXEC [QueryPostType_OptionRecompile] 4;
/*
SQL Server parse and compile time:
CPU time = 5 ms, elapsed time = 5 ms.
*/
Every time that statement runs, it will be compiled again, costing those 5 ms of CPU time.
Summary of the downsides
Each statement with option recompile consumes extra cpu and memory and doesn’t store the execution plan in cache, preventing performance tuners from seeing metrics like total execution count, or total worker time in dm_exec_query_stats.
This view is for system-wide analysis and the counters are cumulative since the last time your server was rebooted. Most scripts against this DMV will store the current values in a table, then wait for a specified amount of time before storing the new current values and comparing the difference.
That technique is great for analyzing overall system health because it gives you insights on every single wait statistic recorded during that time frame. However, I’ve found that this technique can be unreliable when my production systems are heavily pressured for CPU or memory.
As the name might imply, this view shows tasks that are currently waiting, along with their session_id, so you can use dm_exec_requests and dm_exec_sessions with this view to get detailed information on currently waiting sessions.
In my experience, this view is very reliable when there’s TempDB pressure on the system. It’s great, and I’m including my favorite script for this view below.
I don’t know who originally wrote this script, I found it in the “Diagnosing Latch Contention” whitepaper from the Microsoft Customer Advisory Team here.
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc
Hi. Thanks for reading my blog! Seriously, I appreciate every single visit. This post is about my personal experiences this year and next year, for technical content please feel free to skip this post.
Thoughts on 2018
It seems like this year has been extra long. That’s not a bad thing, I enjoyed this year.
At the start of the year, I spoke at SQL Saturday #698, Nashville. This was a great experience, Tammy and Kerry and the rest of the Nashville team run a great event. During this event, it snowed in Nashville which is such a weird experience! But the show still went on, and I met a ton of people.
I continued the year with a ton of speaking. I spoke at SQL Saturday Cleveland, SQL Sat Madison, SQL Sat Chicago, SQL Sat Iowa City, and SQL Sat Minnesota.
I also spoke at the suburban and city user groups in Chicago.
Remote presentations in 2018
I did my first remote presentation for EDMPass, with help from Chris Woods. Then I got a chance to speak at GroupBy.org. Wow. That was the hardest event of all, since I knew it would be immortalized on YouTube for eternity. If you’d like to hear more about the GroupBy conference, please check out my post on the experience.
In summary, 2018 was a great year for speaking. I had a great time and met so many amazing people. Thank you for everyone who have been so welcoming to me.
Speaking in 2019
2019 is going to be a different year. I’ve started to spend more time blogging and I enjoy it a lot!
I’m planning to continue speaking. More to come on this, I plan to put out a offer to speak for groups that need a presenter, and I’ve submitted for SQL Sat Chicago.
If you know you need a presenter in 2019, please reach out on twitter through DMs.
What do I want in 2019
I have three main goals in 2019.
First, I want the senior DBA title. I know it’s just a title, but it means a lot to me. When I met my first mentor, that was his title. In a way, it’s my way of saying I want to reach the level of my old mentor.
Second and third goals will have to be redacted since this blog is public. I want to achieve a monetary goal, and I have a personal goal for life progress. I admire the way that Brent Ozar is open about his goals on ozar.me, so I promise once I’ve achieved those second and third goals that I will blog about them.
If you’re increasing your server’s memory, simultaneously adding more max memory for SQL always seems like a good thing. Let’s talk about what changes when you change the setting for max memory. For the basics, start here.
In SQL Server, increasing max memory will give more memory for data stored in buffer and all sorts of other good things. There is one bad side: your queries that request memory grants may change how much memory they request.
Hopefully your servers have more memory than my blog/presentation laptop. This demo scales, so don’t worry about the small size in my test.
Starting position: max memory at 3 GB
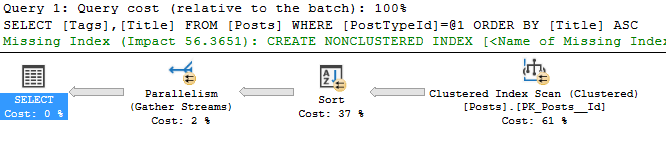
We need a query that wants a memory grant, so I’ll use a query with a sort that returns a lot of rows.
SELECT Tags, Title
FROM Posts
WHERE PostTypeId = 1
ORDER BY Title
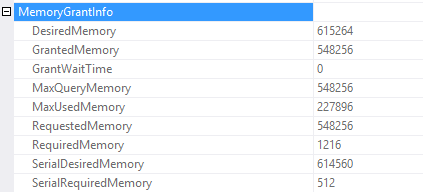
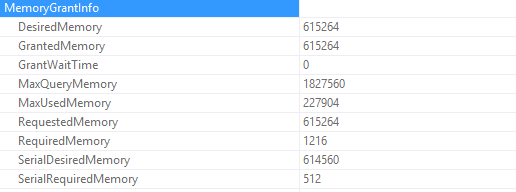
Here’s the memory grant from the actual execution plan’s properties. The query wants 615,264 KB of memory, but it was only granted 548,256.
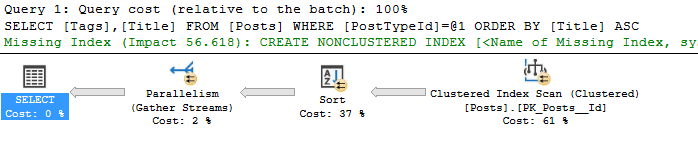
More power! What happens with increased SQL Server max memory?
Same query but with more max memory. In this case, the execution plan stayed the same but the memory grant increased.
This time, all the desired memory was granted. With the lower max memory setting, the query requested 548,256 and now it requests 615,264.
When changing max memory, test
I wanted to write this post to prove that changing SQL Server max memory has an impact on your query’s performance. For this query, a higher memory grant could be a good thing.
If you’re changing SQL Server settings, testing the impact on a test system is recommended.
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.