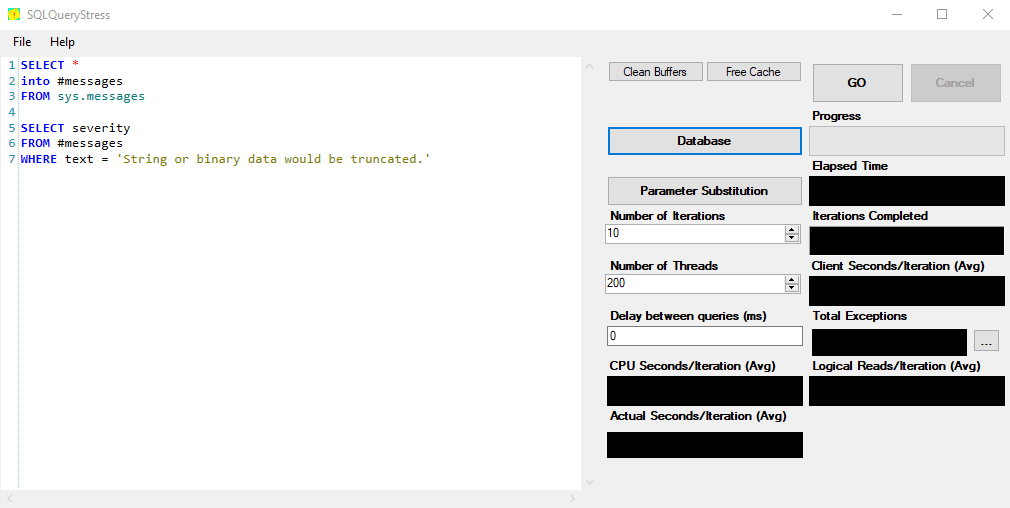
Following up on my post on query_hash, the sql_handle is an attribute that describes the query sent to SQL Server.
While the query_hash ignores parameters and white space, the sql_handle is based on literally every single value passed to the server in the query.
Demo time: creating a sql_handle
I’m re-using the same query from the query_hash example.
--query 1
SELECT *
FROM Posts
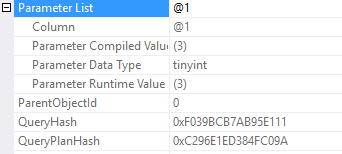
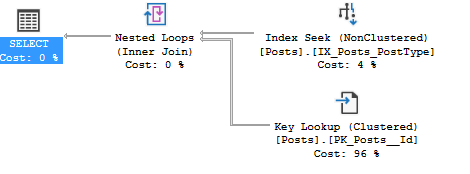
WHERE PostTypeId = 3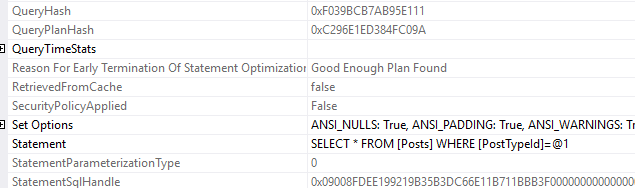
I want to look at that statement sql handle. In the post I call it the sql_handle because that’s the column name in the DMV sys.dm_exec_query_stats. In this execution plan, it’s called the StatementSqlHandle.
I don’t care about the specific characters, I just want to copy that text so we can compare it when I change the SQL text.
0x09008FDEE199219B35B3DC66E11B711BBB3F0000000000000000000000000000000000000000000000000000Now, changing the query text.
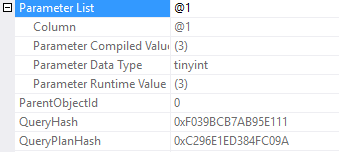
--query 1
SELECT *
FROM Posts
WHERE PostTypeId = 4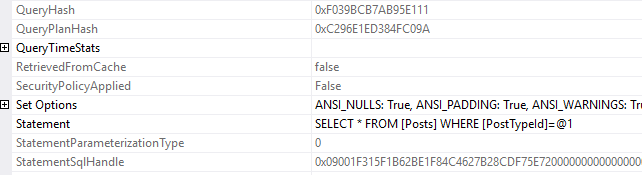
0x09001F315F1B62BE1F84C4627B28CDF75E720000000000000000000000000000000000000000000000000000It’s a different sql handle!
So that’s the interesting part about sql handles. All I did was change the parameter value, and despite having the same query hash, now the query has a new sql handle.
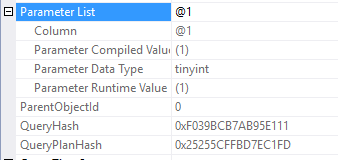
--query 1
SELECT *
FROM Posts WHERE PostTypeId=3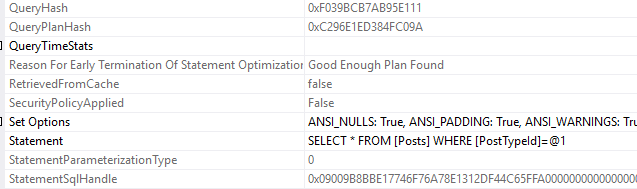
0x09009B8BBE17746F76A78E1312DF44C65FFA0000000000000000000000000000000000000000000000000000There’s the third, new sql handle. That’s the tricky thing about sql handles, they’re so very specific to the exact query that was passed in.
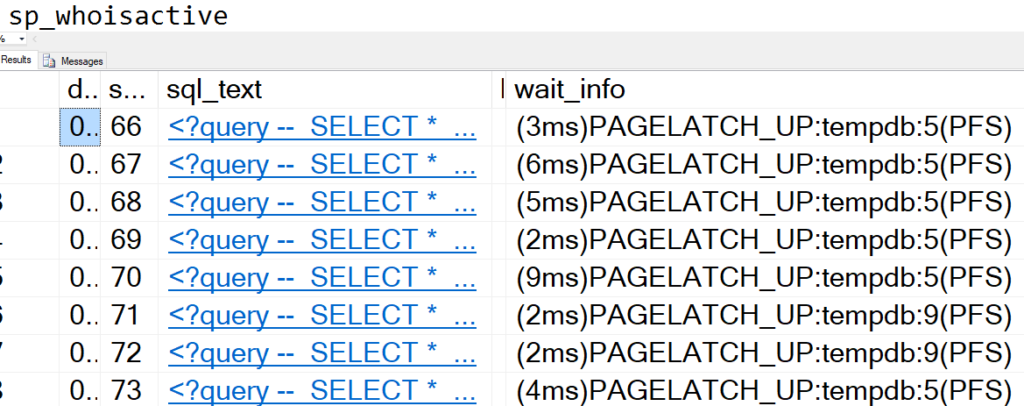
If you’re searching for ad hoc queries
When you’re querying the plan cache, look for queries with the same query_hash. They might each have their own sql_handle.
Finally, here’s all three sql handles side by side
--I deleted the zeros at the end so it's easier to compare
0x09008FDEE199219B35B3DC66E11B711BBB3F
0x09001F315F1B62BE1F84C4627B28CDF75E72
0x09009B8BBE17746F76A78E1312DF44C65FFAThanks for reading! Stay tuned for query plan hash and plan handle, the other descriptors of queries.