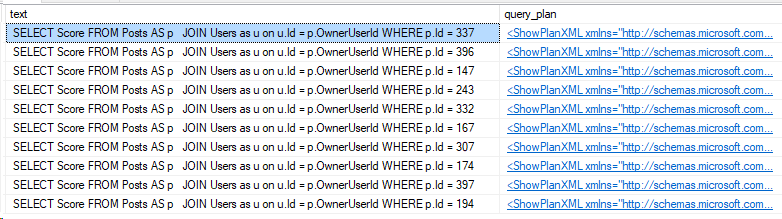
Yesterday’s post talked about single use plans. The statements I’m using are also called ad hoc queries. The alternative to ad hoc would be to create an object like a stored procedure or preparing the statement with a command like sp_prepare or sp_executesql.
The object type will show as “ad hoc” if you’re looking inside sys.dm_exec_cached_plans , which I’ll do later in this post.
Let’s add that DMV to our DMV queries. As a reminder, here’s how I generated my queries:
SELECT TOP 200
N'EXEC(''SELECT Score FROM Posts AS p
JOIN Users as u ON u.Id = p.OwnerUserId
WHERE p.Id = ' + CAST(Id as nvarchar(200)) + ''')'
FROM Posts
ORDER BY IdOkay, now looking in the plan cache:
SELECT TOP 10
cache.size_in_bytes,
cache.objtype,
stext.text,
splan.query_plan
FROM sys.dm_exec_query_stats as stat
CROSS APPLY sys.dm_exec_sql_text(stat.sql_handle) as stext
CROSS APPLY sys.dm_exec_query_plan(stat.plan_handle) as splan
JOIN sys.dm_exec_cached_plans as cache on cache.plan_handle = stat.plan_handle
WHERE stat.query_hash = 0x5F56B6B5EC1A6A6F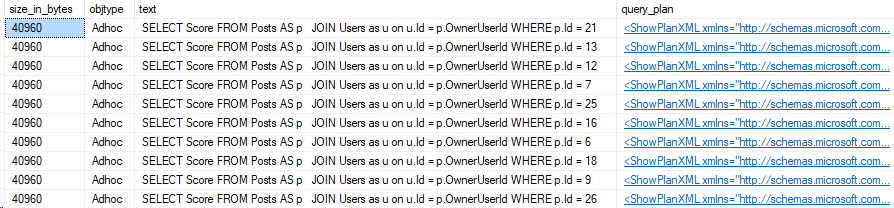
The setting, optimize for ad hoc
I can change the server level setting to On for optimize for ad hoc workloads. Let’s turn that on and try again.
/*
Don't run this in Prod. Always test settings thoroughly before applying
*/
EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1'
GO
RECONFIGURE
GO
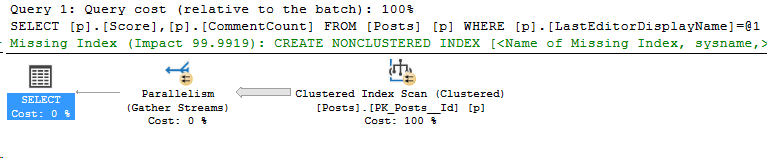
Okay, and now I’ll re-run the test workload from above, and then the plan cache query. Here’s the results:
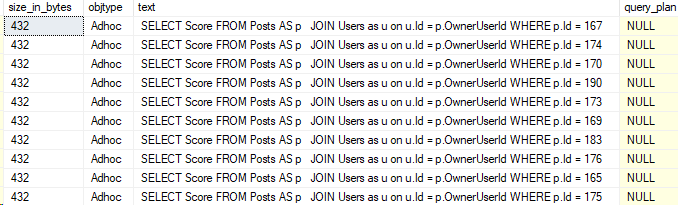
The size in bytes per entry is massively reduced, and these were small execution plans to begin with. However, we lost the entire query plan. That’s not the only cost, but that can have consequences.
Moral of the post
In my opinion, there’s two big downsides to optimize for ad hoc.
First, we lose the query plan information for single use plans. That means that any queries that parse the plan cache (for example, sp_BlitzCache) will not be nearly as useful if your workload is heavily ad hoc. The query plan will be stored if the query runs twice, so this isn’t a total loss.
Second, compiling a plan isn’t free. Optimize for ad hoc stores a stub, but the plan was still compiled for the query when it runs.
Overall, my opinion is that if you’re worried about the memory space used by single use plans, you’ll benefit from the reduced size from optimize for ad hoc workloads.
There’s better solutions, like increasing execution plan re-use. That’s the topic of a future post! Stay tuned.