So far in this series, I’ve been focusing on the Sort operator. It’s pretty easy for demos since I can just write a statement with an ORDER BY and there will be memory requested.
However, there’s another way to get a memory grant easily. That’s when you need to do some aggregation, such as MAX or MIN.
Starting with a demo in StackOverflow2010
SELECT P.OwnerUserId
,COUNT(*) as count_star
FROM Posts as P
GROUP BY P.OwnerUserIdThis query is counting Posts per OwnerUserId, which is the current owner of the Posts.

First, let’s take a look at the query’s overall memory grant.
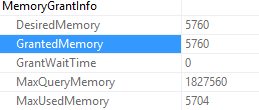
That’s for the whole query. Luckily, this query only has one operator that could use memory, the Hash Match (Aggregate). If you want to know which operators used memory, look for the Memory Fractions property in the execution plan.
Let’s take a look at that Hash Match’s properties
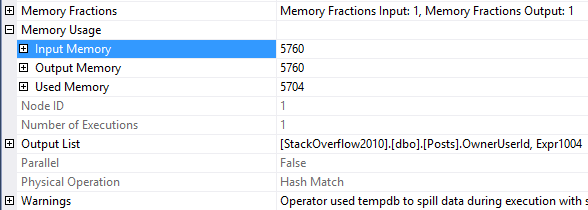
There’s our memory usage! However, it wasn’t enough memory for the query. While the query was running, it had to use some TempDB space to store the rest of the data, which we see in the warnings at the bottom.
TempDB spills deserve their own blog post. For now, I’ll just show exactly how much data was spilled to TempDB:
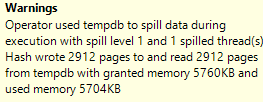
I wanted to write this post to show that using an aggregate like a COUNT will request a memory grant. It’s also important to note that if you include larger columns inside the query, you’ll get a large memory grant.
Using an aggregate like MIN or MAX on a large column
To demo a larger column in this query, I’ll add the Body column from the Posts table. It’s defined as Nvarchar(max).
SELECT P.OwnerUserId
,MIN(Body) as smallest_post
,COUNT(*) as count_star
FROM Posts as P
GROUP BY P.OwnerUserId
Now, the point of this change was not to remove the TempDB spill, but I do find it interesting. Here’s the new memory grant:
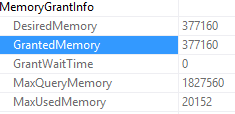

Now that we included a larger column in our aggregate, our query requested a couple hundred extra MBs of memory. It only used 20 MB but requested much more, because the Body column is nvarchar(max). If you’re interested in memory grants and data types, I have a post on that.
That’s the end of this post. If you’re curious about Hash Matches, take a look at Bert Wagner’s post on Hash Match. I’ll look at some other reasons for a memory grant beyond just the aggregates in a later post too. Stay tuned!
Hi, Arthur. I realize that the point of part 6 was to demonstrate the memory grants required to perform aggregate calculations. With that being said, wouldn’t adding a nonclustered index on Posts.OwnerUserId for the first query allow the optimizer to use a Stream Aggregate operator to calculate the row counts for each OwnerUserId and eliminate the memory grant requirement altogether?